Overview
We perform a rigorous, systematic evaluation of automatic-MAS against Chain-of-Thought with Self-Consistency (CoT-SC). Across traditional reasoning datasets and complex agentic tasks such as BrowseComp-Plus, automatic-MAS consistently underperform CoT-SC while incurring up to 10× higher inference cost. To investigate whether task suitability explains this gap, we introduce a diagnostic synthetic dataset, Synthetic Multi-Hop Financial Reasoning (SMFR), designed with explicit sub-task decomposition, context separation, and parallelization potential. Our mechanistic deconstruction of six state-of-the-art frameworks reveals pervasive architectural bloat and functional collapse: complex automatic-MAS workflows degenerate into basic ensembling loops indistinguishable from CoT-SC, exposing a fundamental misalignment with core multi-agent principles.
1 Salesforce AI Research 2 HKUST-Guangzhou 3 UBC 4 NTU
* Equal contribution
Prevailing wisdom posits that Multi-Agent Systems (MAS) are superior to Single-Agent Systems (SAS), citing advantages like context protection, parallel processing and distributed decision-making. However, empirical support for this claim relies primarily on comparisons with SAS baselines using benchmarks that prioritize isolated reasoning tasks, which do not adequately assess these advantages. Focusing on automatic-MAS that are designed for enhanced generalizability over manually-designed counterparts, we perform a rigorous, systematic evaluation against SAS, specifically Chain-of-Thought with Self-Consistency (CoT-SC). Across traditional reasoning datasets and tasks with interactive multi-step workflows (e.g., BrowseComp-Plus), we demonstrate that automatic-MAS consistently underperform CoT-SC despite being up to 10× more expensive. To isolate these failures from limitations inherent to task structure, we introduce a diagnostic synthetic dataset tailored for MAS featuring explicit task decomposition, context separation and parallelization potential. We show that expert-architected MAS consistently outperform automatic-MAS architectures in both raw performance and cost-efficiency on this dataset, demonstrating that existing evaluation frameworks mask critical architectural gaps and inefficiencies of complex MAS by failing to account for the marginal utility of increased computational cost. Critically, systematic deconstruction of automatic-MAS architectures reveals that current automatic-MAS design paradigms produce architectural bloat that prioritizes superficial complexity which does not translate into functional utility, exposing a fundamental misalignment with multi-agent principles.
We demonstrate through systematic benchmarking that automatic-MAS rarely outperform SAS baselines when accounting for cost-efficiency and baseline strength. CoT-SC frequently achieves higher accuracy at less than 10% of the computational cost.
We introduce Synthetic Multi-Hop Financial Reasoning (SMFR), a diagnostic task featuring explicit sub-structures and a gold-standard Expert-MAS to establish an empirical performance upper bound for multi-agent coordination.
We provide a rigorous analysis of synthesized MAS workflows across six frameworks, exposing functional collapse where complex automatic-MAS designs revert to basic single-agent execution in practice.
To investigate whether automatic-MAS deliver consistent, cost-effective advantages over strong SAS baselines, we conduct a large-scale audit spanning four benchmarks (GPQA-Diamond, HLE-Maths, SWE-Bench Lite, and BrowseComp-Plus) across four backbone LLMs: GPT-4o, GPT-5, GPT-OSS-120B, and Gemini-2.5-Pro. We evaluate six representative automatic-MAS frameworks covering both inference-time and optimized paradigms: DyLAN, MAS-Zero, ADAS, AFlow, MaAS, and MAS-Orchestra.
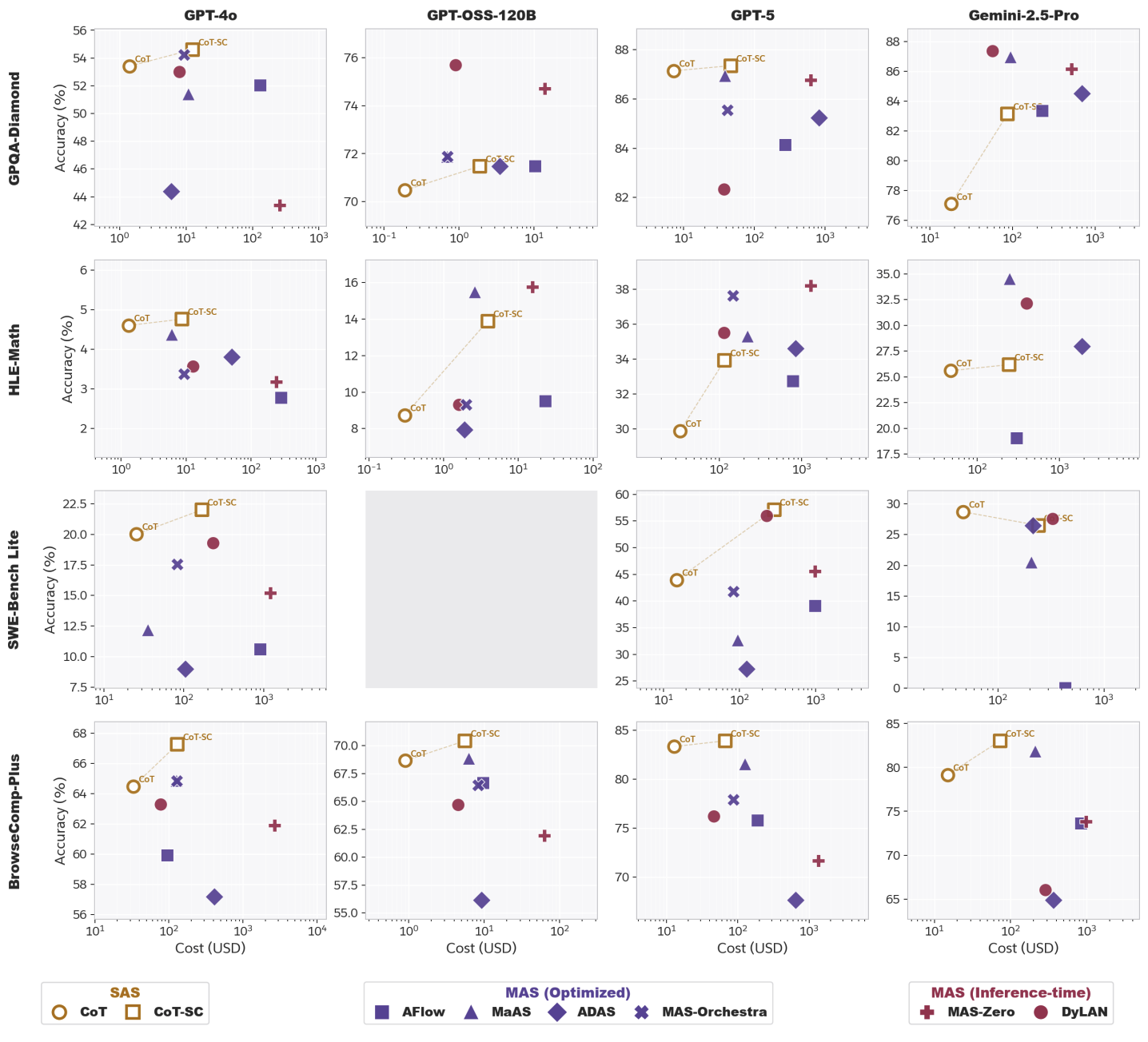
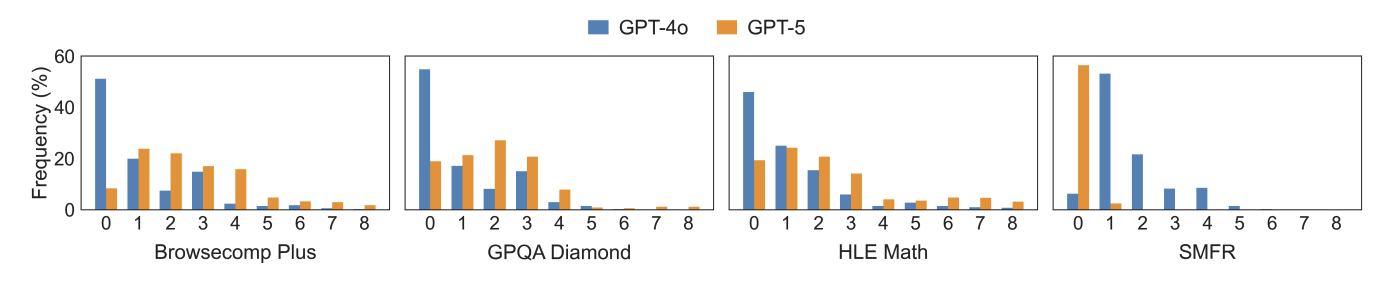
CoT-SC consistently outperforms automatic-MAS frameworks across all benchmarks, frequently achieving higher accuracy at less than 10% of the computational cost. This suggests that architectural complexity is an inefficient substitute for simple stochastic sampling.
Significant MAS uplift only occurs on HLE-Math using GPT-5 and Gemini-2.5-Pro, indicating that architectural complexity only yields benefits when the underlying backbone already possesses the high inherent reasoning capabilities necessary to navigate complex coordination.
Our results directly challenge the prevailing assumption that sophisticated orchestration can elevate weaker models to frontier-level performance. Automatic-MAS provide no consistent improvements for mid-tier models (GPT-4o, GPT-OSS), while a single-agent GPT-5 instance using CoT-SC reliably outperforms the most sophisticated GPT-4o-based automatic-MAS frameworks, including ADAS and AFlow, while consuming less than half the total tokens.
The significant performance-cost gap provides empirical evidence for architectural bloat: the sophisticated multi-agent graphs generated by these frameworks do not translate into functional reasoning gains. Instead, they represent a failure of automated search to discover configurations that outperform unstructured scaling, confirming that current MAS designs have yet to move beyond redundant high-cost iterations.
CoT-SC outperforms automatic-MAS across all standard benchmarking datasets in both accuracy and cost-effectiveness. However, existing works have critiqued the use of benchmarks predicated on simple input-output flows for evaluating multi-agent coordination. To isolate task suitability as a contributing factor, we introduce the Synthetic Multi-Hop Financial Reasoning (SMFR) dataset: a diagnostic task with explicit sub-structures, context-heavy inputs, and clear opportunities for parallelization and specialization.
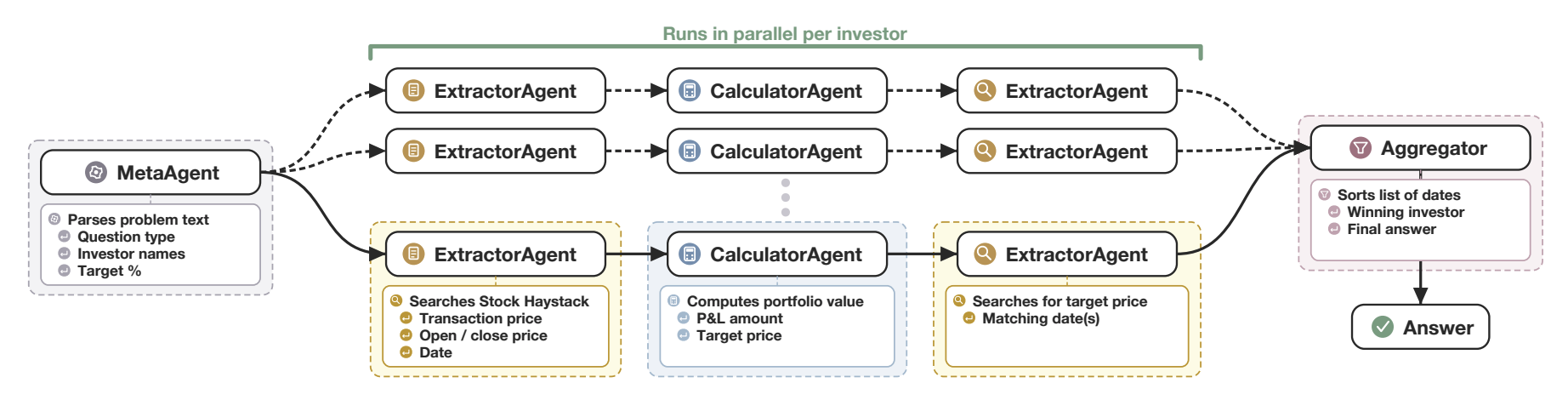
Each SMFR problem is built programmatically from historical US equity prices. We first sample stock tickers, transaction types (buy/sell), price types (open/close), the number of investors (2–6), and a target profit/loss percentage (0.1–2.0%). The resulting instance presents an agent with a stock price haystack (historical open/close prices for B companies over a 30-day window) and a set of investor transactions. For each investor, the agent must extract relevant transactions, compute profit and loss to derive a target price, retrieve the matching date(s), and finally aggregate across investors to select the winner according to an earliest- or latest-date criterion.
The pipeline is deliberately parallelizable per investor and resists shortcut strategies: correct solutions require multi-step context extraction and numerical reasoning rather than pattern matching. Problems are generated from real price distributions but remain immune to data contamination, since each instance is a synthetic composition. The dataset contains 588 test samples and 16 validation samples, balanced across transaction types, aggregation logic, and target percentages.

To establish a competitive reference upper bound, we design an Expert-MAS that enforces a strict separation between context processing and logical control. A Meta-Agent first parses the problem topology (question type, investor names, target percentage) into a structured schema. A deterministic Python executor then orchestrates specialized sub-agents in parallel: an ExtractorAgent retrieves transaction and price data from the haystack, a CalculatorAgent computes portfolio value and target prices, and a second ExtractorAgent locates matching dates. An Aggregator agent sorts results and selects the winning investor. By offloading coordination to deterministic code, Expert-MAS eliminates the orchestration noise that plagues automatic-MAS designs.
We evaluate CoT-SC, six automatic-MAS frameworks, and Expert-MAS on SMFR across GPT-4o, GPT-OSS-120B, and GPT-5. If task suitability were the primary bottleneck for automatic-MAS, we would expect them to close the gap on this explicitly agentic benchmark. Instead, automatic-MAS consistently fail to surpass CoT-SC efficiency, while Expert-MAS achieves substantially better accuracy-cost trade-offs on stronger backbones.
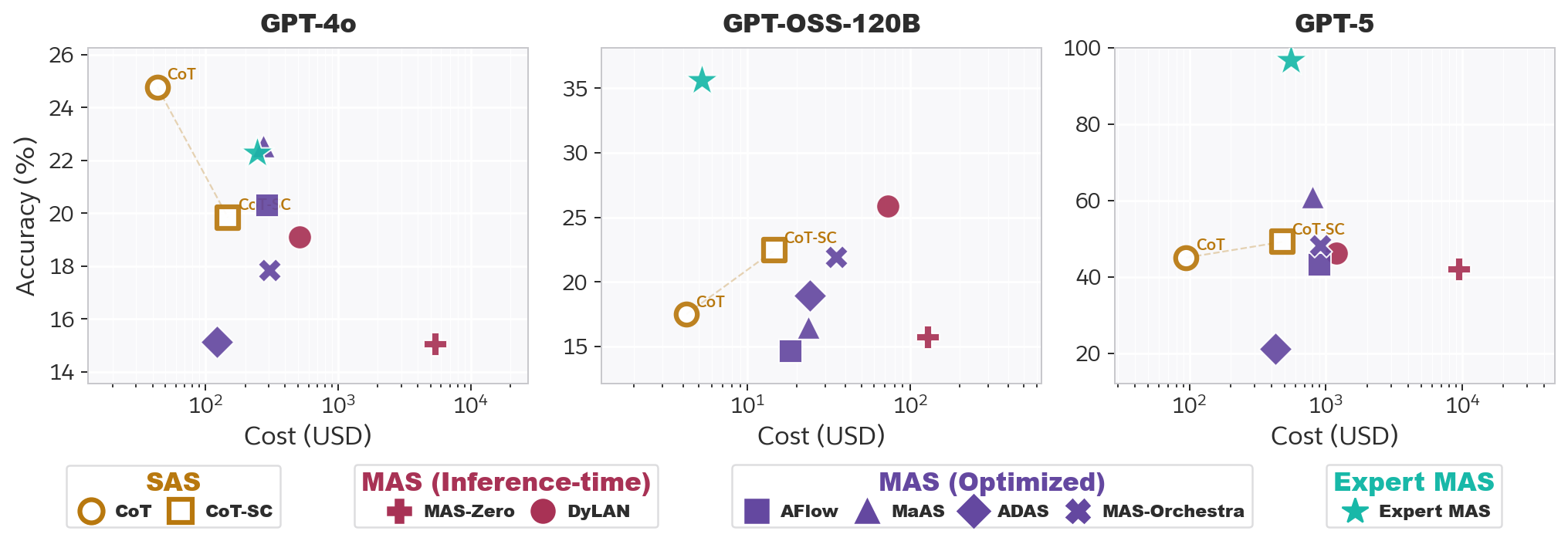
Despite explicit agentic requirements (multi-step planning, state tracking, and long-context retrieval), automatic-MAS consistently fail to surpass CoT-SC efficiency on SMFR, proving that task suitability is not the root cause of their underperformance. Instead, these systems incur massive computational overhead without proportional gains. Expert-MAS, by contrast, achieves substantial improvements with cost comparable to CoT-SC: GPT-OSS improves from 22.4% to 36.0%, while GPT-5 jumps from 49.1% to a near-perfect 96.7%.
The sole exception is GPT-4o, where persistent calculation and retrieval failures bottleneck the system regardless of orchestration. This reinforces our finding that MAS require a threshold baseline competency to be effective. Thus, while the multi-agent paradigm is fundamentally viable, current automatic-MAS frameworks fail to exploit task-specific opportunities effectively or economically.
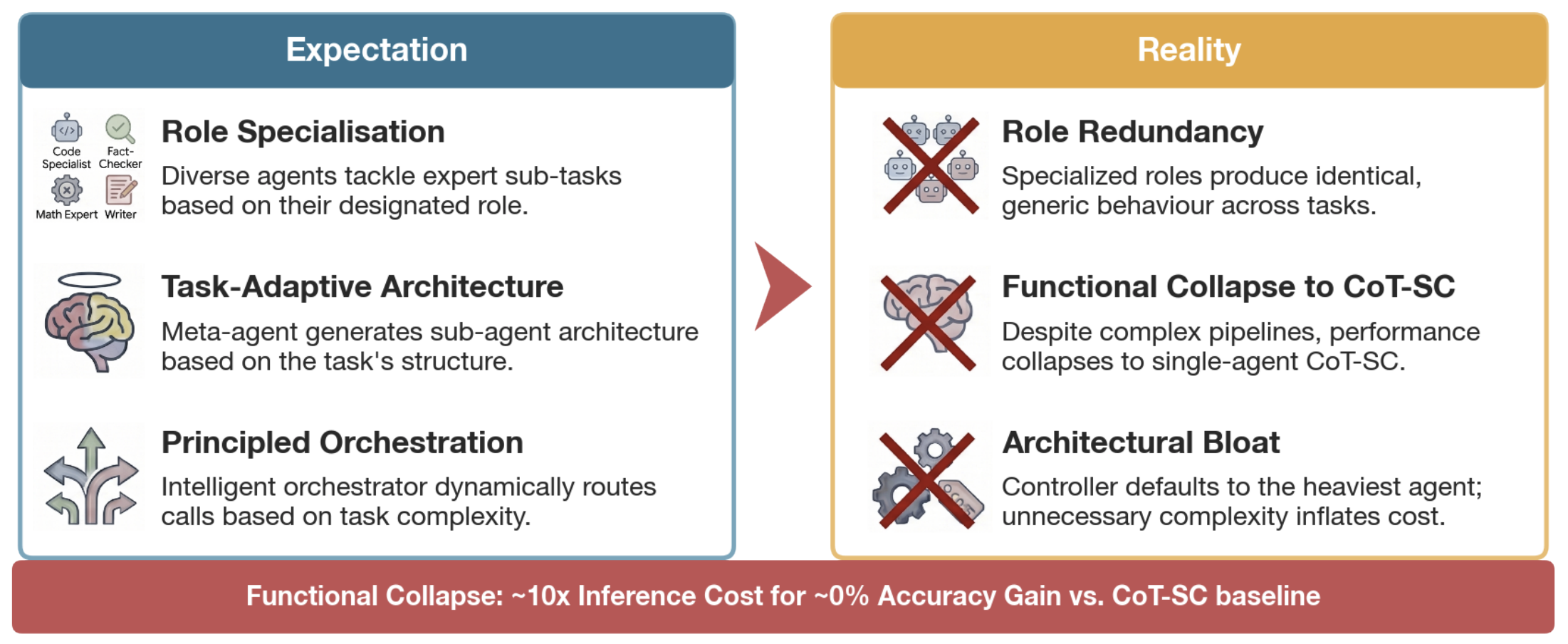
While our results establish a clear efficiency gap between single- and multi-agent systems, they do not reveal whether the internal mechanisms of MAS (role specialization, consensus, routing) provide latent benefits that justify their complexity. To address this, we deconstruct the generated architectures and investigate whether their features contribute meaningfully to the reasoning process. We find that in most automatic-MAS workflows, these mechanisms are either sub-optimal or purely decorative rather than manifestations of emergent intelligence.
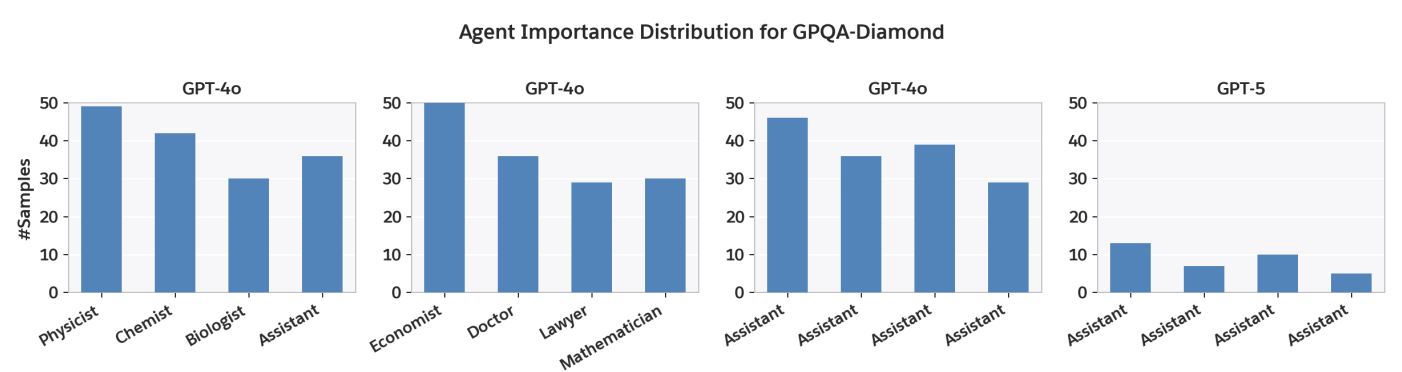
DyLAN posits that performance is driven by agent diversity, yet this fails to manifest in practice. Agents reach immediate, unanimous consensus in ~70% of GPT-4o cases and >90% of GPT-5 cases, effectively functioning as a unanimous CoT-SC baseline rather than a dynamic negotiation. When interaction does occur, task-specific roles provide no marginal utility: an all-assistant configuration achieved better accuracy than task-specific experts (54.4% vs. 53.4%).
The verifier disproportionately favors earlier entries in the context window: GPT-4o selects the initial block in over 45% of instances. Outputs from later search rounds are rarely selected, accounting for less than 15% of final decisions, effectively turning subsequent worker agents into “expensive witnesses” that incur full inference costs while exerting near-zero causal influence on the output.
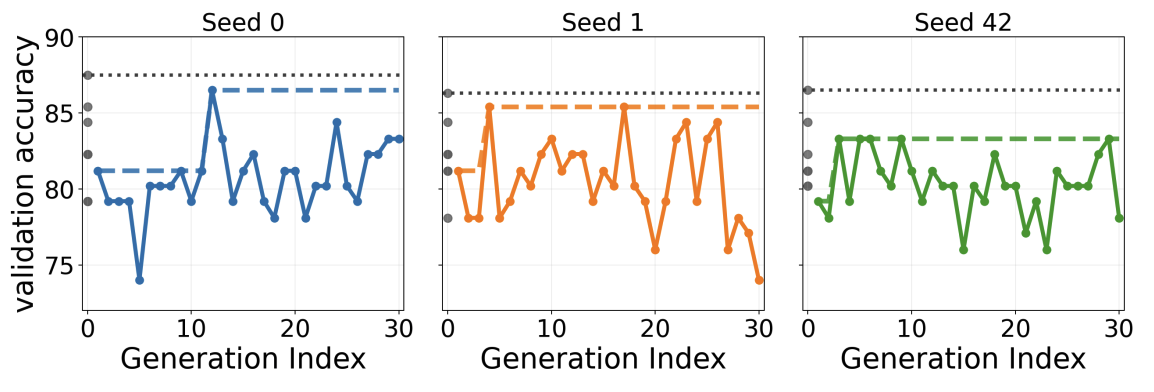
Our motif analysis reveals that the primary positive signal originates from Self-consistency motifs; specialized coordination motifs yield negligible gains. On GPQA-Diamond, architectures incorporating Self-consistency achieved a mean accuracy of 82.19% (+1.34% over the global average). ADAS functions as a heuristic explorer rather than a principled optimizer, where performance gains reflect stochastic “lucky” iterations rather than structural evolution.

Across 14 final workflows generated by GPT-4o, GPT-5, and GPT-OSS-120B on five datasets, 50% (7/14) adopted a structure that simply iterates a single custom prompt three times before aggregation, which is functionally identical to standard CoT-SC; four of these underperformed the CoT-SC baseline. This confirms that automated search often converges on rediscovering CoT-SC-style sampling under more complex labels rather than inventing novel multi-agent strategies.

With highly capable base models, the accuracy gradient flattens to ~1/K, causing the controller to ignore task-specific logic and collapse into two distinct failure modes: (i) Cost-Minimizing Collapse on BrowseComp-Plus (74.2% trivial I/O calls) and (ii) Stochastic Stalling on GPQA-Diamond, where negligible cost differentials trap the controller in its initialized near-uniform distribution.

The system largely ignores its diverse agent pool, converging on a rigid binary preference for high-overhead Debate and Reflexion agents. The orchestrator fails to scale agent complexity to task difficulty: despite GPQA-Diamond posing a lower reasoning ceiling than HLE-Math, the system exhibits a higher reliance on Debate agents for the former (84.9%) than the latter (79.2%). These behaviors confirm that automated orchestrators do not learn task-adaptive strategies, but instead settle into static, greedy local minima.
Our evaluation reveals a systematic divergence between the theoretical complexity of MAS frameworks and their empirical execution. While intended to foster emergent collaboration, current automatic-MAS paradigms frequently result in mechanistic trivialization: sophisticated architectural designs collapse into elementary single-agent workflows.
A primary driver of this collapse is the reliance on CoT and CoT-SC as the fundamental building blocks of MAS. While these primitives ensure generalization and leverage ensembling effects, the resulting architectures fail to implement them efficiently. Rather than synergistic coordination, frameworks like AFlow and ADAS settle into structural degeneration, rediscovering basic ensembling motifs under the guise of optimized multi-agent graphs. The ~10× increase in inference cost thus buys little more than a redundant, poorly routed approximation of standard CoT-SC.
As model capability scales, the MAS advantage further erodes due to two reinforcing factors. Signal Saturation: in models like GPT-5, accuracy gradients flatten, causing controllers (MaAS) to lose the signal necessary for nuanced routing, collapsing into cheap shortcuts or static policies. Positional and Primacy Biases: verifiers and controllers (MAS-Zero, DyLAN) disproportionately favor early reasoning steps, effectively terminating the multi-agent benefit before interaction can occur. The success of Expert-MAS on SMFR reinforces that multi-agent coordination excels only when architectures are specifically engineered to exploit parallelizable sub-problems or context protection. Future research should pivot away from black-box automated graph generation, which defaults to redundant ensembling, and toward the mechanistic interpretability of agent interactions. We argue that to move beyond creating “expensive witnesses,” MAS must be evaluated on their structural fidelity: the degree to which assigned agentic roles exert measurable causal influence on the final decision. Without such grounding, increased architectural complexity serves only to mask computational inefficiency.
Our systematic evaluation identifies a critical efficiency gap in modern MAS design, where architectural complexity often masks a fundamental functional collapse into simpler, stochastic baselines. By introducing the SMFR benchmark and isolating the mechanistic failures of six major frameworks, we provide a roadmap for more principled, cost-effective agentic design. Our architectural deconstruction reveals that current automatic-MAS workflows frequently degenerate into redundant ensembling loops functionally identical to CoT-SC. Ultimately, moving beyond “expensive witnesses” requires a pivot from black-box graph searching towards architectures grounded in verifiable task decomposition and causal role-alignment.
@misc{xx
}